previously, we discussed/mapped all the fundamental Windows PE structures and parsing capabilities needed by every other component for our custom minidumper tool. in this part, we’ll define the minidump format structures that build upon the PE definitions. following that, we’ll learn how to implement the actual dumping logic using the types defined.
data types
in the context of minidumps, data types refer to the structured representations of various elements within the dump file. these types are defined to mirror the Windows minidump format specs. an example of this is the MINIDUMP_TYPE enumeration
, aka minidumpapiset.h. this enum identifies the type of information written to the minidump file by the MiniDumpWriteDump function
.
MINIDUMP_TYPE
typedef enum _MINIDUMP_TYPE {
MiniDumpNormal = 0x00000000,
MiniDumpWithDataSegs = 0x00000001,
MiniDumpWithFullMemory = 0x00000002,
MiniDumpWithHandleData = 0x00000004,
MiniDumpFilterMemory = 0x00000008,
MiniDumpScanMemory = 0x00000010,
MiniDumpWithUnloadedModules = 0x00000020,
MiniDumpWithIndirectlyReferencedMemory = 0x00000040,
MiniDumpFilterModulePaths = 0x00000080,
MiniDumpWithProcessThreadData = 0x00000100,
MiniDumpWithPrivateReadWriteMemory = 0x00000200,
MiniDumpWithoutOptionalData = 0x00000400,
MiniDumpWithFullMemoryInfo = 0x00000800,
MiniDumpWithThreadInfo = 0x00001000,
MiniDumpWithCodeSegs = 0x00002000,
MiniDumpWithoutAuxiliaryState = 0x00004000,
MiniDumpWithFullAuxiliaryState = 0x00008000,
MiniDumpWithPrivateWriteCopyMemory = 0x00010000,
MiniDumpIgnoreInaccessibleMemory = 0x00020000,
MiniDumpWithTokenInformation = 0x00040000,
MiniDumpWithModuleHeaders = 0x00080000,
MiniDumpFilterTriage = 0x00100000,
MiniDumpWithAvxXStateContext = 0x00200000,
MiniDumpWithIptTrace = 0x00400000,
MiniDumpScanInaccessiblePartialPages = 0x00800000,
MiniDumpFilterWriteCombinedMemory,
MiniDumpValidTypeFlags = 0x01ffffff
} MINIDUMP_TYPE;
MINIDUMP_HEADER
the main header structure that appears at the beginning of every minidump file is MINIDUMP_HEADER
. it contains the signature (MINIDUMP_SIGNATURE = 0x504d444d or “MDMP” in ascii), version, the number of streams, timestamp, and flags (seen above).
typedef struct _MINIDUMP_HEADER {
ULONG32 Signature;
ULONG32 Version;
ULONG32 NumberOfStreams;
RVA StreamDirectoryRva;
ULONG32 CheckSum;
union {
ULONG32 Reserved;
ULONG32 TimeDateStamp;
};
ULONG64 Flags;
} MINIDUMP_HEADER, *PMINIDUMP_HEADER;
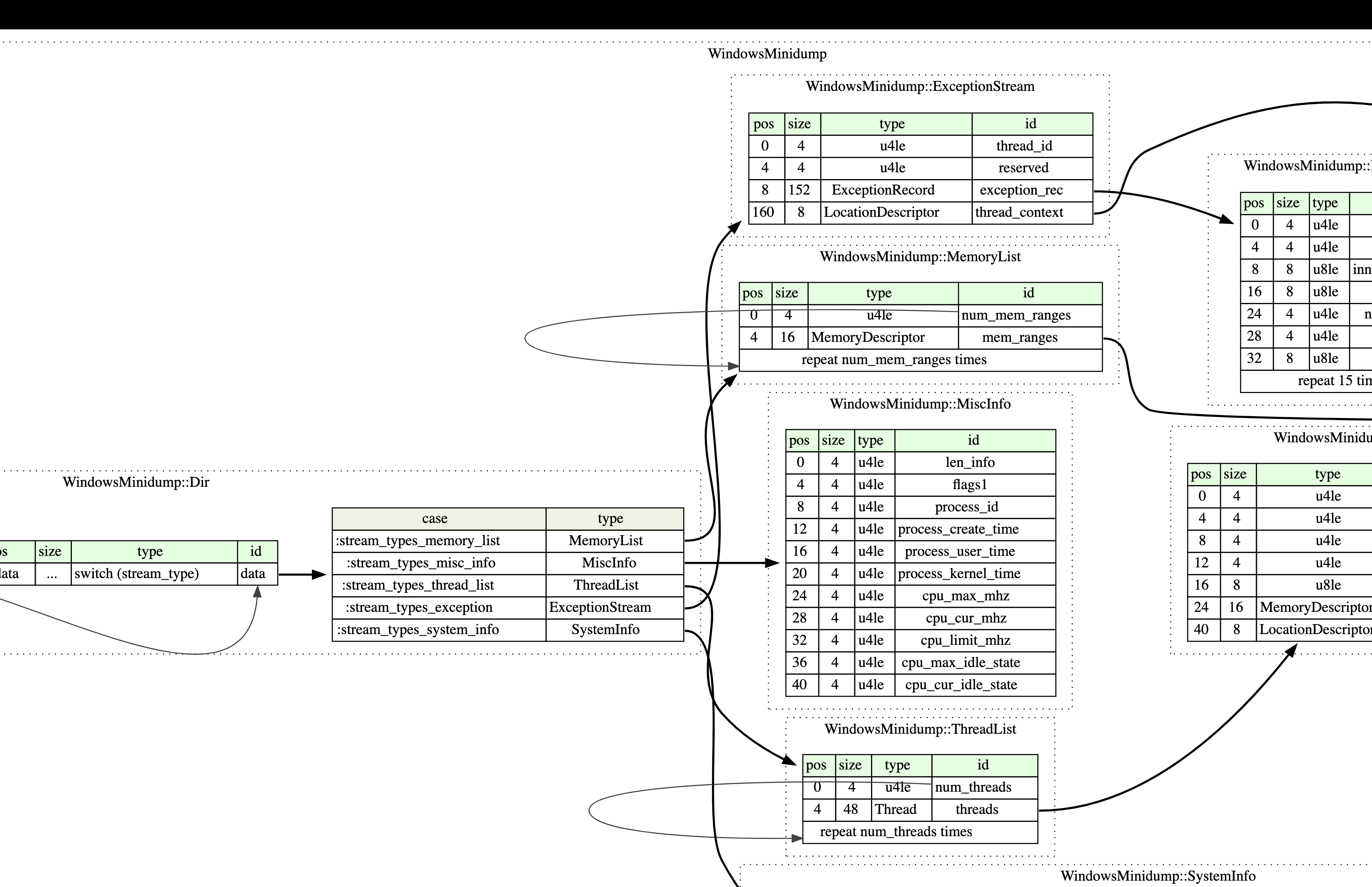
MINIDUMP_DIRECTORY
MINIDUMP_DIRECTORY
contains the information needed to access a specific data stream in a minidump file. it defines the location + type of each stream in the minidump.
typedef struct _MINIDUMP_DIRECTORY {
ULONG32 StreamType;
MINIDUMP_LOCATION_DESCRIPTOR Location;
} MINIDUMP_DIRECTORY, *PMINIDUMP_DIRECTORY;
MINIDUMP_MEMORY_DESCRIPTOR
the MINIDUMP_MEMORY_DESCRIPTOR
defines a region (range) of memory in the minidump.
typedef struct _MINIDUMP_MEMORY_DESCRIPTOR {
ULONG64 StartOfMemoryRange;
MINIDUMP_LOCATION_DESCRIPTOR Memory;
} MINIDUMP_MEMORY_DESCRIPTOR, *PMINIDUMP_MEMORY_DESCRIPTOR;
MINIDUMP_THREAD
MINIDUMP_THREAD contains information about a thread, including its ID, stack information, and context.
typedef struct _MINIDUMP_THREAD {
ULONG32 ThreadId;
ULONG32 SuspendCount;
ULONG32 PriorityClass;
ULONG32 Priority;
ULONG64 Teb;
MINIDUMP_MEMORY_DESCRIPTOR Stack;
MINIDUMP_LOCATION_DESCRIPTOR ThreadContext;
} MINIDUMP_THREAD, *PMINIDUMP_THREAD;
MINIDUMP_MODULE
MINIDUMP_MODULE represents a loaded module (DLL or an EXE) in the process.
typedef struct _MINIDUMP_MODULE {
ULONG64 BaseOfImage;
ULONG32 SizeOfImage;
ULONG32 CheckSum;
ULONG32 TimeDateStamp;
RVA ModuleNameRva;
VS_FIXEDFILEINFO VersionInfo;
MINIDUMP_LOCATION_DESCRIPTOR CvRecord;
MINIDUMP_LOCATION_DESCRIPTOR MiscRecord;
ULONG64 Reserved0;
ULONG64 Reserved1;
} MINIDUMP_MODULE, *PMINIDUMP_MODULE;
data serialization
data serialization is the process of converting in-memory data structures into a format that can be written to disk or transmitted over a network. the minidump file itself is a container, which contains a number of typed “streams”, which contain some data according to its type attribute.
minidumps preserve the endianness (little- or big-) of the platform they were generated on, since they contain lots of raw memory from the process. the serialization process must handle this to ensure cross-platform compatibility.
some structures in the minidump format require specific alignment. serialization must account for this as well, by adding padding wherever necessary.
since we’re going to be writing this in rust, there needs to be type conversion between native rust types and the binary representation required by the minidump format.
streams
streams are the core organizational units within a minidump file. each stream contains a specific type of data about the dumped process.
stream types, identified by a unique integer, basically describe the type of stream. for example:
3: ThreadListStream, 4: ModuleListStream, 5: MemoryListStream, 6: ExceptionStream or 7: SystemInfoStream.
the minidump file contains a directory of streams , allowing quick access to specific data without parsing the entire file.
many streams follow a common “List” format, consisting of a count followed by an array of entries, like MinidumpMemoryList (maps the crashing program’s runtime addresses, such as $rsp to ranges of memory in the minidump), MinidumpModuleList (includes info on all the modules/libraries that were linked into the crashing program; this enables symbolication, as you can map instruction addresses back to offsets in a specific library’s binary), or MinidumpThreadList (includes the registers and stack memory of every thread in the program at the time of the crash; this enables generating backtraces for every thread).
the minidump format also allows for custom stream types, enabling extensions to the format without breaking compatibility.
to sum it up, we’ll need to refine rust structures that accurately represent these different data types, implement serialization logic for each type, organize the captured data into appropriate streams, and create a stream directory that allows efficient access to each stream.
structure design
recalling that the minidump format is a structured representation of process memory and state, our format begins with a header that Windows debugging engines use to validate and parse dump files.
pub(crate) struct MinidumpHeaderR {
pub(crate) signature: u32, // 'MDMP' (0x504d444d) in ASCII
pub(crate) version: u32, // Format version identifier
pub(crate) number_of_streams: u32, // Count of data streams
pub(crate) stream_directory_rva: RVA32<MINIDUMP_DIRECTORY>, // Pointer to stream listings
pub(crate) checksum: u32, // Optional error checking value
pub(crate) _time_date_stamp: u32, // UNIX timestamp of dump creation
pub(crate) flags: u64, // Dump content indicators
pub(crate) minidump_header_rva: *mut MINIDUMP_HEADER, // Self-reference for validation
}
the signature field contains ‘MDMP’ in ASCII (0x504d444d), which debuggers use as a magic number to identify valid dump files. the version field indicates the minidump format version - our implementation uses version 0x0000000A, corresponding to Windows 10 and later formats.
when this header is serialized, it’s written to the start of the dump file.
impl MinidumpHeaderR {
pub(crate) fn serialize(&mut self, buf: &mut Vec<u8>) {
let minidump_header = MINIDUMP_HEADER {
Signature: self.signature,
Version: self.version,
NumberOfStreams: self.number_of_streams,
StreamDirectoryRva: self.stream_directory_rva.0,
CheckSum: self.checksum,
Anonymous: Default::default(),
Flags: self.flags,
};
module state + PE image capture
the module capturing system records the state of loaded modules (DLLs and EXEs) in the target process. this involves more than just recording names and addresses - we’ll need to capture the base address where the module is loaded, the size of the module in memory, the full module content from memory (might differ from disk), full path + name information, version, and debug data locations.
pub(crate) struct MinidumpModuleR {
pub(crate) base: u64, // Module's base address in process space
pub(crate) size: u64, // Size of loaded module
pub(crate) bytes: Vec<u8>, // Actual module content from memory
pub(crate) name: String, // Module's full path
pub(crate) start_offset: RVA64<MINIDUMP_MODULE>, // Location in dump file
}
the module data is serialized through a complex process that preserves Windows PE format requirements:
fn serialize(&mut self, buf: &mut Vec<u8>) {
let minidump_mod = MINIDUMP_MODULE {
BaseOfImage: self.base,
SizeOfImage: self.size as u32,
CheckSum: 0,
TimeDateStamp: 0,
ModuleNameRva: 0,
VersionInfo: Default::default(),
CvRecord: Default::default(),
MiscRecord: Default::default(),
Reserved0: 0,
Reserved1: 0,
};
this serialization process writes the module information in a format that Windows debugging tools expect. the ModuleNameRva field is particularly important - it’s fixed up after writing the name data:
pub(crate) fn fixup(&mut self, buf: &mut Vec<u8>) {
let target_mod = self.start_offset.get_mut(buf.as_mut_ptr() as usize);
let target_name = &self.name;
// convert name to UTF-16 for Windows compatibility
let mut utf16_buf: Vec<u8> = Vec::new();
for c in target_name.encode_utf16() {
utf16_buf.extend_from_slice(&c.to_le_bytes());
}
memory range capture system
the memory range system implements the actual process memory capture mechanism. this involves tracking both the virtual address space layout and the actual memory content.
pub(crate) struct MinidumpMemory64ListR {
pub(crate) _base_rva: RVA64<MINIDUMP_MEMORY_DESCRIPTOR64>,
pub(crate) memory_ranges: Vec<MinidumpMemoryDescriptor64R>,
pub(crate) list_ptr: Option<*mut MINIDUMP_MEMORY64_LIST>
}
each memory range represents a contiguous block of memory in the process.
pub(crate) struct MinidumpMemoryDescriptor64R {
pub(crate) start_of_memory_range: u64, // Virtual address in process
pub(crate) data_size: u64, // Size of memory block
pub(crate) bytes: Vec<u8>, // Actual memory content
}
the memory capture process involves sophisticated filtering of memory regions.
if (mem_info.State & MEM_COMMIT.0) == MEM_COMMIT.0
&& (mem_info.Type & MEM_MAPPED.0) != MEM_MAPPED.0
&& ((mem_info.Protect & PAGE_NOACCESS.0) != PAGE_NOACCESS.0
&& (mem_info.Protect & PAGE_EXECUTE.0) != PAGE_EXECUTE.0
&& (mem_info.Protect & PAGE_GUARD.0) != PAGE_GUARD.0)
{
// region accepted for capture
}
this filtering ensures we’ll only capture committed memory pages (i.e. those actually backing physical memory). it’ll also skip memory-mapped files to avoid capturing disk content, and respect memory protection (skip inaccessible pages, avoid executable memory that might trigger security mechanisms and handle guard pages that can cause exceptions).
when memory is read, we use ReadProcessMemory with careful error handling.
let res = unsafe {
ReadProcessMemory(
h_target_proc,
mem_info.BaseAddress as *const _,
buffer.as_mut_ptr() as *mut _,
mem_info.RegionSize,
Some(&mut read),
)
};
memory range serialization
the memory range serialization process is complex because it must maintain proper alignment and ordering while handling variable-sized data. the process begins with the stream header.
pub(crate) fn serialize(&mut self, buf: &mut Vec<u8>, dir_info: &mut MinidumpDirectoryListR) {
let offset_start = buf.len();
let number_of_ranges = self.memory_ranges.len();
let total_size = 16 + std::mem::size_of::<MINIDUMP_MEMORY_DESCRIPTOR64>() * number_of_ranges;
the size calculation (16 + descriptor size * range count) has to account for 8 bytes for NumberOfMemoryRanges, 8 bytes for BaseRva, and the size of each memory descriptor structure.
the actual memory data is written sequentially after all descriptors.
let mem_dmp_start = offset_start + total_size;
let first_e = self.memory_ranges[0].get();
let minidump_mem_list = MINIDUMP_MEMORY64_LIST {
NumberOfMemoryRanges: number_of_ranges as u64,
BaseRva: mem_dmp_start as u64,
MemoryRanges: [first_e; 1],
};
this structure is critical because Windows debuggers use the BaseRva field to locate the actual memory contents. the memory ranges are written in two phases: descriptor and content.
descriptor phase
for idx in 1..self.memory_ranges.len() {
let mem = &mut self.memory_ranges[idx];
mem.serialize(buf);
}
content phase
pub(crate) fn fixup(&mut self, buf: &mut Vec<u8>) {
println!("Memory dmp start actually is {:#x}", buf.len());
for idx in 0..self.memory_ranges.len() {
let mem = &self.memory_ranges[idx];
buf.extend_from_slice(mem.bytes.as_slice());
}
}
this two-phase approach ensures that all memory descriptors are contiguous in the file, followed by all memory contents, making the dump file efficiently parseable.
system information capture
the system information capture process is more complex than simply querying API functions. to avoid detection and API hooks, we directly query the registry.
MinidumpSystemInfoR: directly querying registry
pub(crate) struct MinidumpSystemInfoR {
pub(crate) processor_architecture: u16,
pub(crate) processor_level: u16,
pub(crate) processor_revision: u16,
pub(crate) number_of_processors: u8,
pub(crate) product_type: u8,
pub(crate) major_version: u32,
pub(crate) minor_version: u32,
pub(crate) build_number: u32,
pub(crate) platform_id: u32,
pub(crate) csd_version_rva: RVA32<MINIDUMP_STRING>,
// ... additional fields
}
the version information is obtained through direct registry access.
fn get_likely_os_ver() -> OSVERSIONINFOEXW {
let mut hkey = HKEY::default();
let ntstat = unsafe {
RegOpenKeyExA(
HKEY_LOCAL_MACHINE,
PCSTR::from_raw("SOFTWARE\\Microsoft\\Windows NT\\CurrentVersion\0".as_ptr()),
0,
KEY_READ | KEY_QUERY_VALUE,
&mut hkey,
)
};
we read multiple values to construct accurate version information.
let mut major_version = 0;
let mut major_version_size = std::mem::size_of::<u32>();
let ntstat = unsafe {
RegQueryValueExA(
hkey,
PCSTR::from_raw("CurrentMajorVersionNumber\0".as_ptr()),
None,
Some(&mut REG_DWORD),
Some(&mut major_version as *mut u32 as *mut _),
Some(&mut major_version_size as *mut usize as *mut _),
)
};
this direct registry access approach serves several purposes. for one, it bypassess potential API hooks and gets the actual installed version. it also accesses additional version details that aren’t available via standard APIs.
directory stream management
the directory stream system maintains the relationship between different data streams in the dump.
pub(crate) struct MinidumpDirectoryListR {
pub(crate) directory: Vec<MinidumpDirectoryR>,
}
pub(crate) struct MinidumpDirectoryR {
pub(crate) stream_type: u32,
pub(crate) _location: MINIDUMP_LOCATION_DESCRIPTOR,
pub(crate) start_offset: RVA64<MINIDUMP_DIRECTORY>,
}
each directory entry points to a specific type of data in the dump. the stream types include:
ModuleListStream (0x4): list of loaded modules
Memory64ListStream (0x9): 64-bit memory ranges
SystemInfoStream (0x7): system information
ThreadListStream (0x3): thread information
the directory serialization process maintains these relationships.
fn serialize_directories(
buf: &mut Vec<u8>,
header: &mut MinidumpHeaderR,
) -> MinidumpDirectoryListR {
let mut dirs = MinidumpDirectoryListR::default();
let minidump_header = unsafe { &mut *header.minidump_header_rva };
minidump_header.StreamDirectoryRva = buf.len() as u32;
each directory entry maintains a stream type identifier, a location descriptor (offset and size), and the RVA to the actual stream data.
RVA (Relative Virtual Address) implementation
the RVA system is fundamental to both PE files and minidump formats. our implementation uses generic types to provide type safety and proper pointer arithmetic.
#[derive(Copy, Clone, Default)]
#[repr(transparent)]
pub struct RVA32<T: ?Sized>(pub u32, pub core::marker::PhantomData<T>);
#[derive(Copy, Clone, Default)]
#[repr(transparent)]
pub struct RVA64<T: ?Sized>(pub u64, pub core::marker::PhantomData<T>);
the PhantomData marker is crucial here - it provides type information without affecting the memory layout. this enables the compiler to enforce type safety when dereferencing RVAs. the implementation provides safe access methods.
impl<T> RVA32<T> {
pub fn get(&self, base_address: usize) -> &T {
unsafe { &*((base_address + self.0 as usize) as *const T) }
}
pub fn get_mut(&mut self, base_address: usize) -> &mut T {
unsafe { &mut *((base_address + self.0 as usize) as *mut T) }
}
}
this system ensures that:
RVAs can only be dereferenced with the correct base address
type information is preserved through the dereference operation
mutable and immutable access is properly controlled
memory alignment requirements are maintained
memory reading + validation
the actual process memory reading involves careful handling of Windows memory protection and state.
reading process memory
pub(crate) fn create_memory_desc64_list(h_proc: HPSS, h_target_proc: HANDLE) -> MinidumpMemory64ListR {
let mut memory_desc64_list = MinidumpMemory64ListR::default();
loop {
let mut mem_info = PSS_VA_SPACE_ENTRY::default();
let memory_entry_slice = unsafe {
std::slice::from_raw_parts_mut(
&mut mem_info as *mut PSS_VA_SPACE_ENTRY as *mut u8,
std::mem::size_of::<PSS_VA_SPACE_ENTRY>(),
)
};
validating memory
the memory validation process checks multiple attributes.
if (mem_info.State & MEM_COMMIT.0) == MEM_COMMIT.0 &&
(mem_info.Type & MEM_MAPPED.0) != MEM_MAPPED.0 &&
((mem_info.Protect & PAGE_NOACCESS.0) != PAGE_NOACCESS.0 &&
(mem_info.Protect & PAGE_EXECUTE.0) != PAGE_EXECUTE.0 &&
(mem_info.Protect & PAGE_GUARD.0) != PAGE_GUARD.0)
{
each check serves a specific purpose:
MEM_COMMITensures the page has physical storage allocatedMEM_MAPPEDcheck avoids reading memory-mapped filesPAGE_NOACCESScheck prevents access violationsPAGE_EXECUTEcheck avoids potential security triggersPAGE_GUARDcheck prevents stack guard page exceptions
reading validated memory regions
when reading validated memory regions
let mut buffer: Vec<u8> = Vec::with_capacity(mem_info.RegionSize as usize);
for _ in 0..mem_info.RegionSize {
buffer.push(0);
}
let mut read = 0;
let res = unsafe {
ReadProcessMemory(
h_target_proc,
mem_info.BaseAddress as *const _,
buffer.as_mut_ptr() as *mut _,
mem_info.RegionSize,
Some(&mut read),
)
};
the reading process becomes:
- pre-allocate a buffer to avoid reallocations
- maintain proper alignment for the target memory
- track actual bytes read vs requested
- handle partial reads correctly
string handling + unicode support
string handling in minidumps requires careful attention to Windows Unicode requirements.
pub(crate) fn fixup(&mut self, buf: &mut Vec<u8>) {
let target_name = &self.name;
let mut utf16_buf: Vec<u8> = Vec::new();
let target_name = target_name.trim_end_matches('\0');
for c in target_name.encode_utf16() {
utf16_buf.extend_from_slice(&c.to_le_bytes());
}
the MINIDUMP_STRING structure requires specific handling.
let minidump_str = MINIDUMP_STRING {
Length: target_len as u32,
Buffer: [0; 1],
};
buf.extend_from_slice(unsafe {
std::slice::from_raw_parts(
&minidump_str.Length as *const u32 as *const u8,
std::mem::size_of::<u32>(),
)
});
now: string length is properly recorded, buffer is properly aligned, the format matches Windows debugger expectations, and Unicode strings are properly terminated.
stream directory organization
the minidump format organizes data through a stream directory system. each stream represents a different type of process information.
let dir_info = dir_info.directory
.iter_mut()
.find(|x| x.stream_type == ModuleListStream.0 as u32)
.unwrap();
let target_dir = dir_info
.start_offset
.get_mut(buf.as_mut_ptr() as *mut _ as usize);
the stream directory maintains crucial offset information.
target_dir.Location.DataSize = module_list_size as u32;
target_dir.Location.Rva = current_offset as u32;
this organization serves several purposes:
allows random access to specific data types
maintains proper alignment of all data
enables stream size validation
facilitates proper memory mapping when loaded by debuggers
module list serialization
the module list stream requires careful ordering and alignment.
pub(crate) fn serialize(&mut self, buf: &mut Vec<u8>, dir_info: &mut MinidumpDirectoryListR) {
let current_offset = buf.len();
let module_list_size = std::mem::size_of::<MINIDUMP_MODULE>() *
self.modules.len() + 4; // +4 for NumberOfModules
let module_list = MINIDUMP_MODULE_LIST {
NumberOfModules: self.modules.len() as u32,
Modules: [MINIDUMP_MODULE::default(); 1],
};
the serialization process maintains crucial PE metadata:
base addresses of modules
module sizes in memory
module names and paths
time stamps and checksums
debug information references
each module requires specific fixups:
pub(crate) fn fixup(&mut self, buf: &mut Vec<u8>) {
for module in &mut self.modules {
let target_mod = module.start_offset.get_mut(buf.as_mut_ptr() as usize);
// Module name handling
let target_name = &module.name;
let mut utf16_buf: Vec<u8> = Vec::new();
for c in target_name.encode_utf16() {
utf16_buf.extend_from_slice(&c.to_le_bytes());
}
memory list organization
the memory list stream requires careful organization to maintain proper memory mapping capabilities.
pub(crate) fn serialize(&mut self, buf: &mut Vec<u8>, dir_info: &mut MinidumpDirectoryListR) {
let offset_start = buf.len();
let mem_dmp_start = offset_start + std::mem::size_of::<MINIDUMP_MEMORY64_LIST>();
let minidump_mem_list = MINIDUMP_MEMORY64_LIST {
NumberOfMemoryRanges: self.memory_ranges.len() as u64,
BaseRva: mem_dmp_start as u64,
MemoryRanges: [self.memory_ranges[0].get(); 1],
};
the memory organization process:
records the number of memory ranges
calculates proper RVAs for memory content
maintains proper alignment for all memory blocks
preserves memory protection information
orders memory ranges for efficient access
final dump assembly
now, the final dump assembly process brings all streams together.
pub fn create_custom_minidump(h_proc: HPSS) -> Result<Vec<u8>, ()> {
let mut clone_info = PSS_VA_CLONE_INFORMATION::default();
let mut header = create_header();
let mut sysinfo_stream = create_sysinfo_stream();
let mut module_list = create_module_list(h_proc, h_target_proc);
let mut memory_desc64_list = create_memory_desc64_list(h_proc, h_target_proc);
the assembly process follows a specific order:
header serialization
directory creation
system information stream
module list stream
memory descriptor list
actual memory content
the ordering is crucial because the header must point to valid stream directories. the streams must also maintain proper RVA chains and the memory content must align with descriptors. and finally, all offsets must be calculable from the header.
the final validation process includes:
// Verify header signature
if header.signature != 0x504d444d {
return Err(());
}
// Verify stream count matches directory
if header.number_of_streams as usize != dir_info.directory.len() {
return Err(());
}
// Verify memory range consistency
for range in &memory_desc64_list.memory_ranges {
if range.data_size as usize != range.bytes.len() {
return Err(());
}
}
now we can be sure that the dump file is properly formatted, all streams are correctly referenced, memory ranges are consistent, string data is properly encoded, and the dump can be loaded by Windows debuggers!